From asking for a change in gun laws to calling out shootings at an Ariana Grande concert, Eminem’s lyrics in Music To Be Murdered By have been surrounded by controversies since the day it launched last week. Yet, this is not unusual for anyone familiar with Eminem’s work. He is popular for lyrics that do not conform to political correctness and swears that will make your mom upset.
Just a week later and Music To Be Murdered By has topped the Billboard 200 making Eminem the only artist having 10 studio albums that topped the chart. The times have changed since Em first launched his studio album. Let’s see if his music has changed too!
In this one, I have covered the trends for Eminem’s 10 studio albums. This includes audio analysis, changing feature trends with albums, and a look at the positivity of Em’s albums.
I have primarily used data from Spotify’s API using multiple endpoints for albums and tracks. I supplemented the data with stats from Billboard and calculations from this post.
Trends in Positivity for all albums
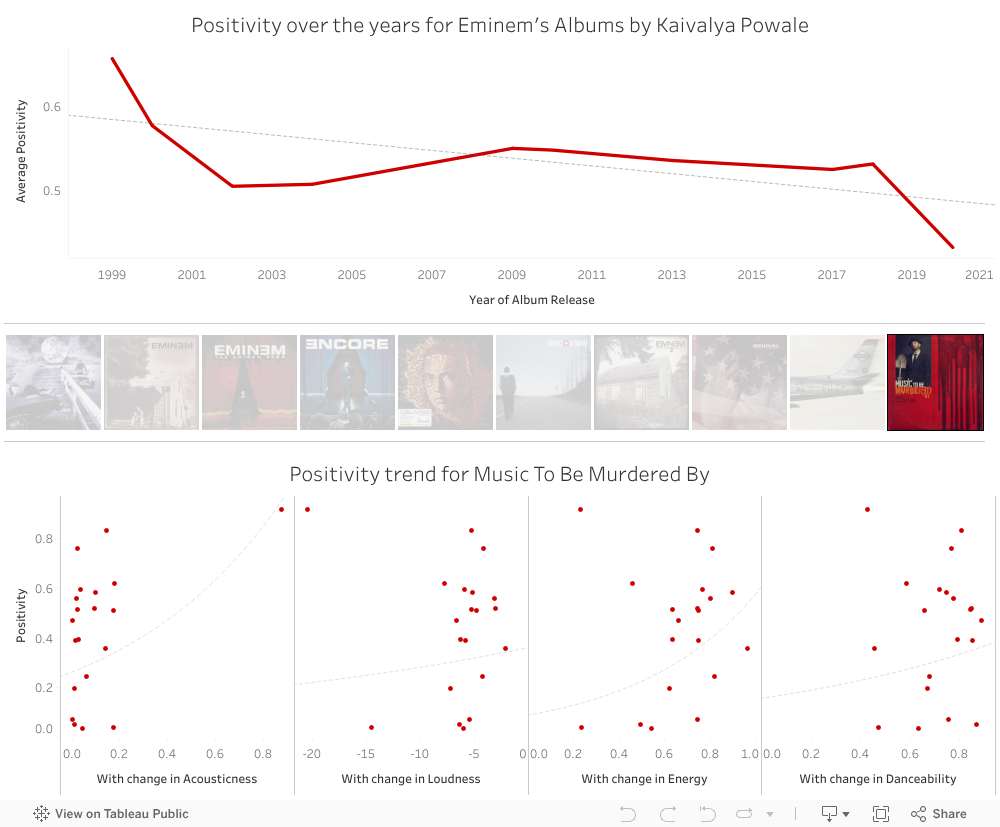
I created a dashboard that shows the average Positivity of Eminem’s albums over the years. This feature was obtained from Spotify’s Web API endpoint. Spotify calls this metric Valence which reflects on positivity (hence I have called it that to simplify things). Here’s how Spotify has defined this metric
“A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).”
Every point on the plot represents one song in the album.

It is clear that over the years Em’s songs are perceived to be more and more negative. Music To Be Murdered By is by far the most negatively perceived album according to the audio analysis. And it seems so too in reality. With songs like ‘Darkness’ and ‘In Too Deep’, Eminem has addressed a lot of sadness around in this one.

The chart above tells us that, in general, the Positivity increases with an increase in Acousticness, Loudness, Energy, and Danceability of the songs. That makes sense as more acoustic and danceable songs are the effect of pop collaborations whereas louder and more energetic songs tend to sound happier.

Here’s how the Positivity trends with respect to Speechiness of the songs i.e. with an increase in words, the songs are more positive. That sounds unusual and pretty much unlike Em!
This is not true for all albums though. Whereas Positivity increases with Marshall’s words in his latest, for albums like Relapse the positivity actually decreases with more words.


It still seems highly unusual for Eminem’s words to be perceived more positively. Let’s see how have those words changed over time!
Words and Song Durations
Over time, the album duration is going down which shows that Eminem is making shorter albums. That’s for sure with just 13 songs in Kamikaze as compared to an average of 19 songs per album for others.
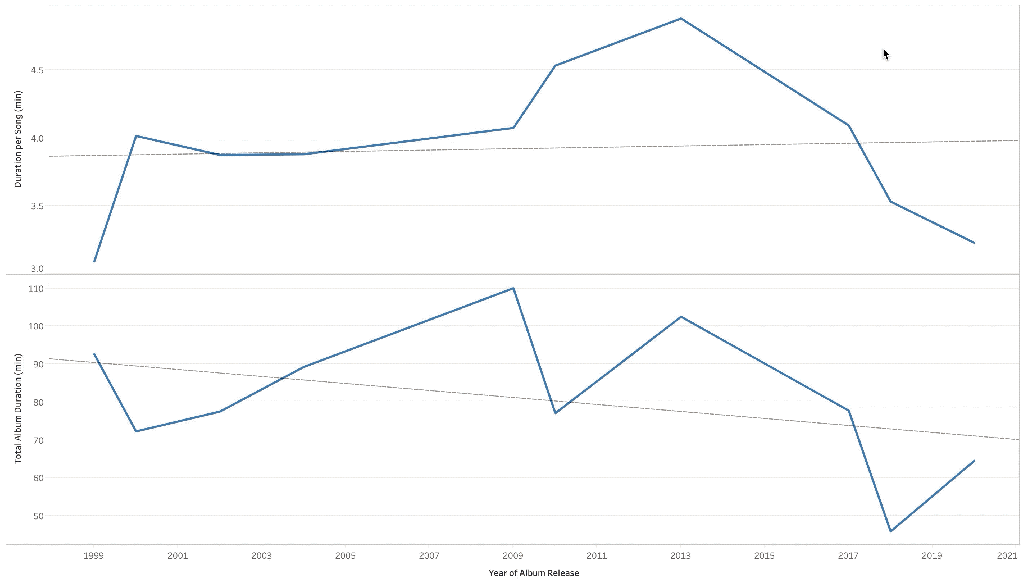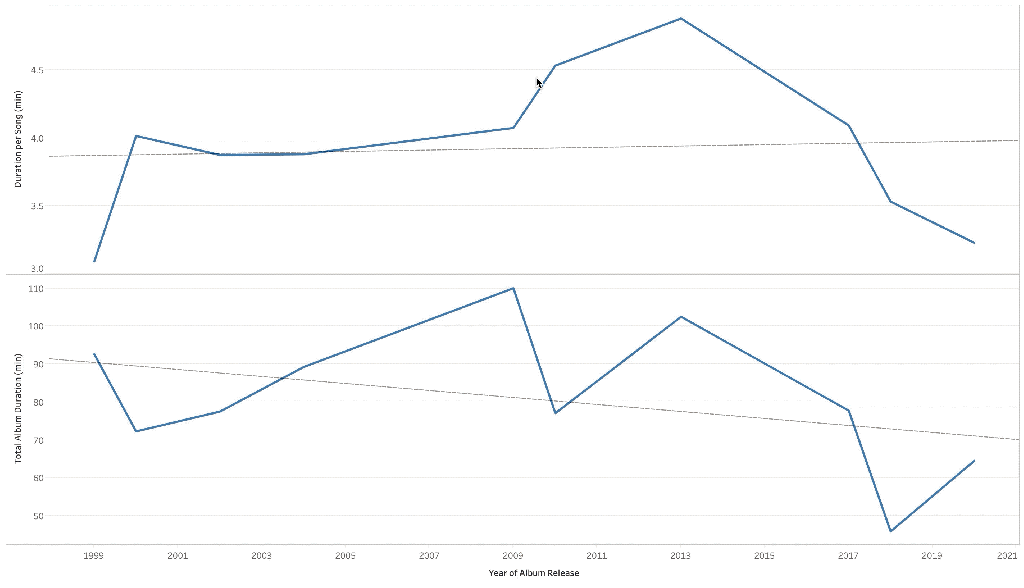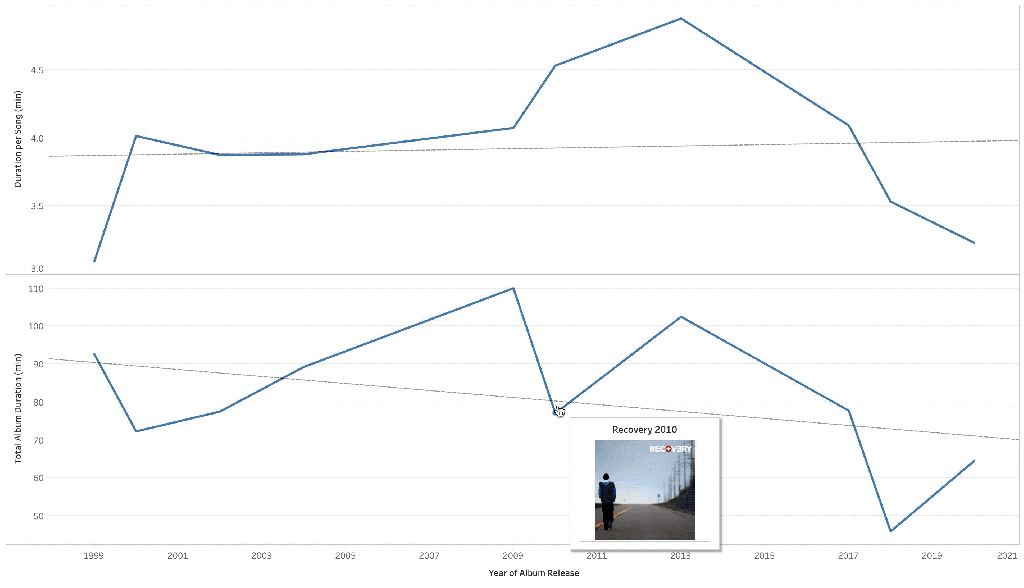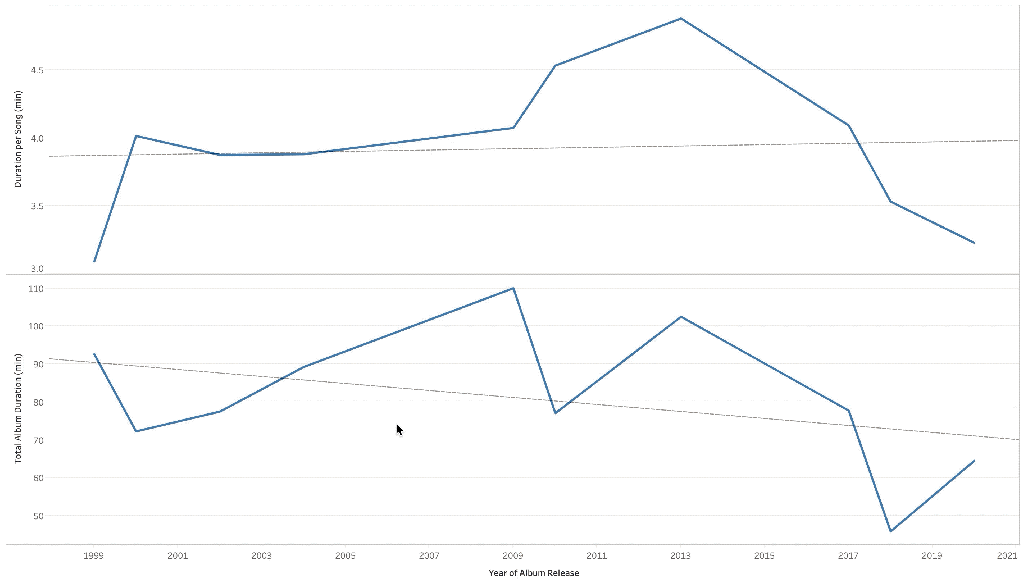
When we look at song duration, it tells the same story. The song duration has gone down over the years. This is a phenomenon affecting the industry as an influence of pop culture.
It is worth noting that the song duration bumped around Marshall Mathers LP 2. This album was Em’s comeback album and featured longer songs like ‘Rap God’ and included a couple of skits pulling up the average duration.
Another possible explanation is that the song duration is decreasing as Eminem is spittin’ out words faster and faster with every release. This is shown the likes of ‘Rap God’ in MMLP2 and now in ‘Godzilla’ with Em making history by packing a whopping 7.23 words per second!
Eminem swears like he wants to upset your mom. His work is widely popular for being laden with swear words, controversial, offensive, and misogynistic lyrics. Let’s see how the swear words in his songs have changed over time!
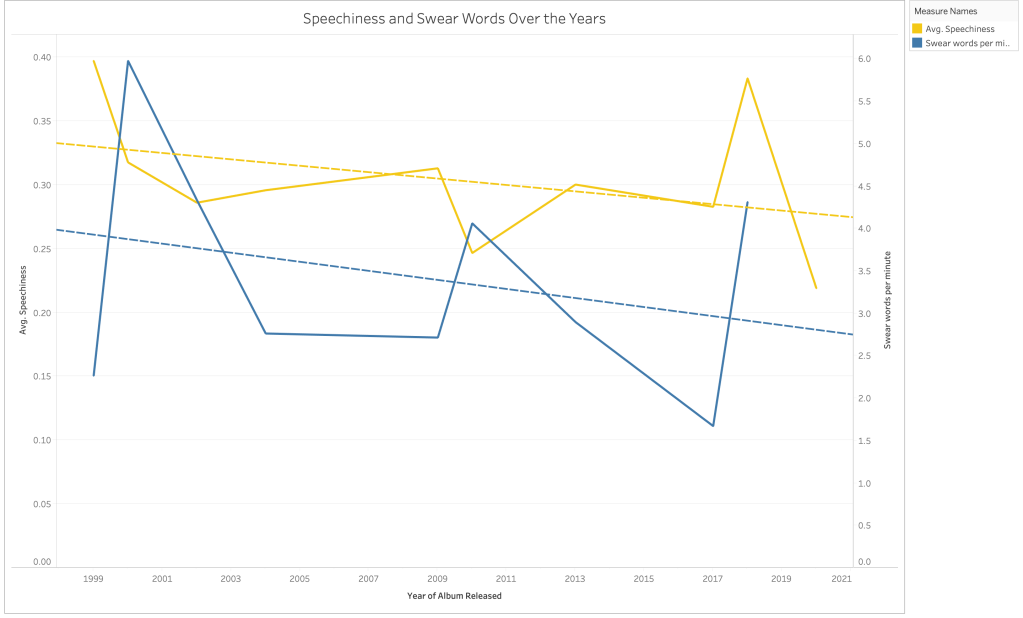
Eminem’s most controversial work has been during the early 2000s. This chart is a proof of that. The number of swear words used has gone down over time except for the uptick in Kamikaze. Over the years, he has calmed down and made a few amends; like forgiving his mom.
Speechiness shows that the ratio of words to music has also gown down over the years. As both the trend lines suggest, Eminem is using lesser words, more music, and definitely lesser swear words. Would that make your mom happy?
Features over the years
A major part of Spotify’s API is the audio feature analysis by its music intelligence company The Echo Nest. This data is calculated through its proprietary algorithm and not much is shared about how the features are calculated.
These features give a great overview of a song, album, or playlist though. It is worthwhile to take a look at them. So, I went ahead and created a simple dashboard for you to explore all the features firsthand! Take a look.

That’s it for this one! I will be sharing the code to acquire this data soon. Until then, learn how to access Spotify’s API or check out my GitHub to see if I have uploaded the code to my repo. Thanks for reading!
Update 05/11/2020: You can download the Python notebook and data directly from here. The notebook has all the guidelines for the project.
You can also go to my GitHub for more instructions. You can return here to look at visualizations!