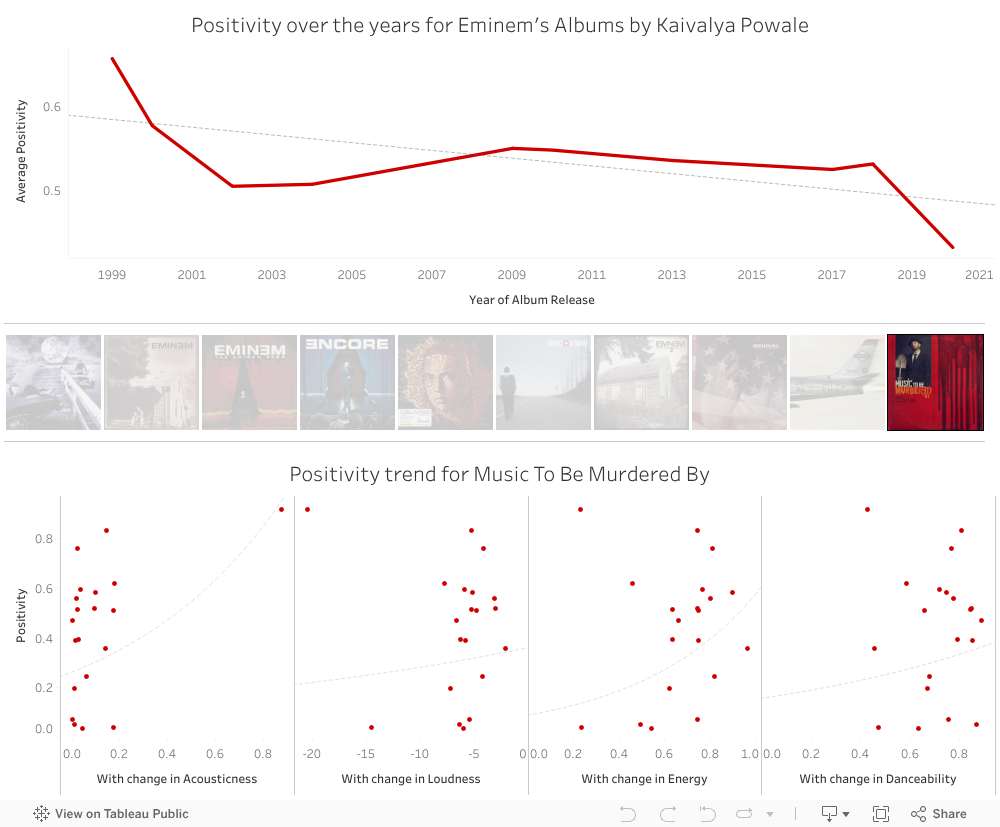
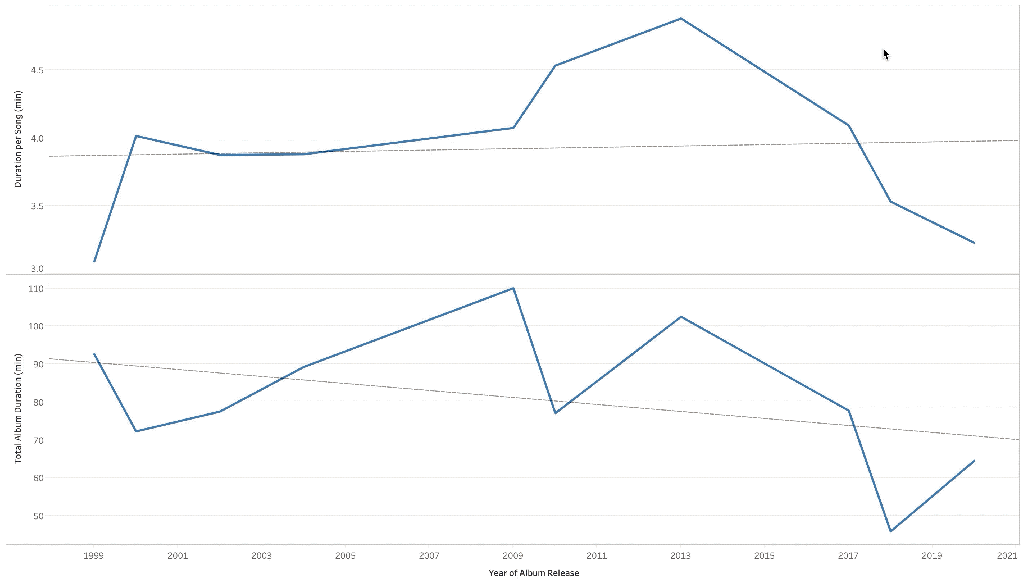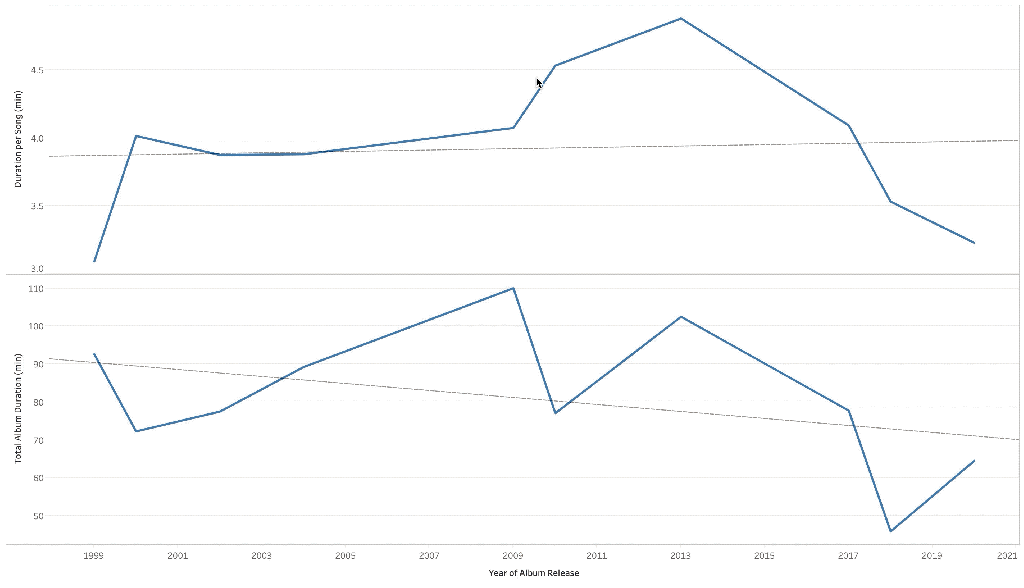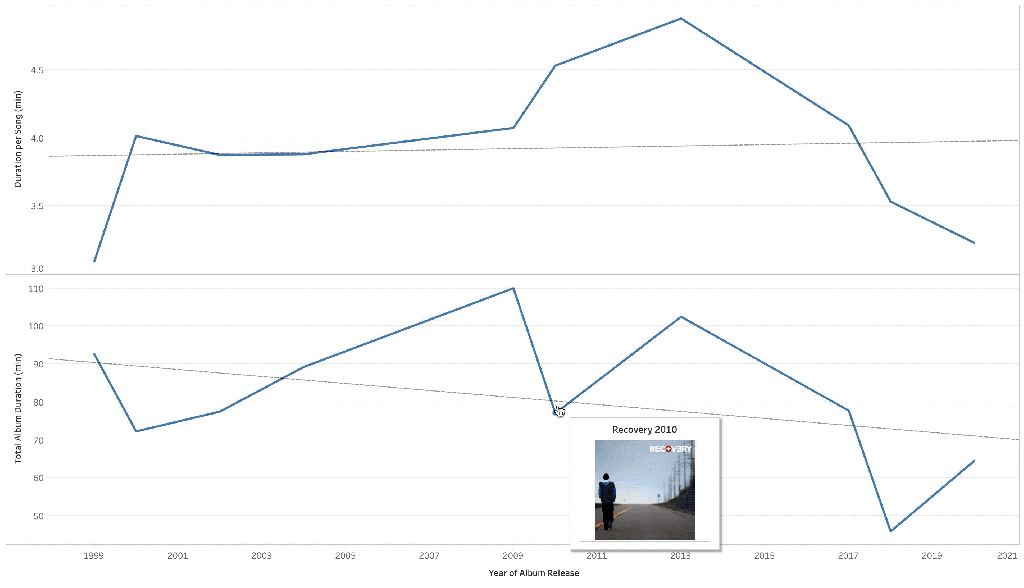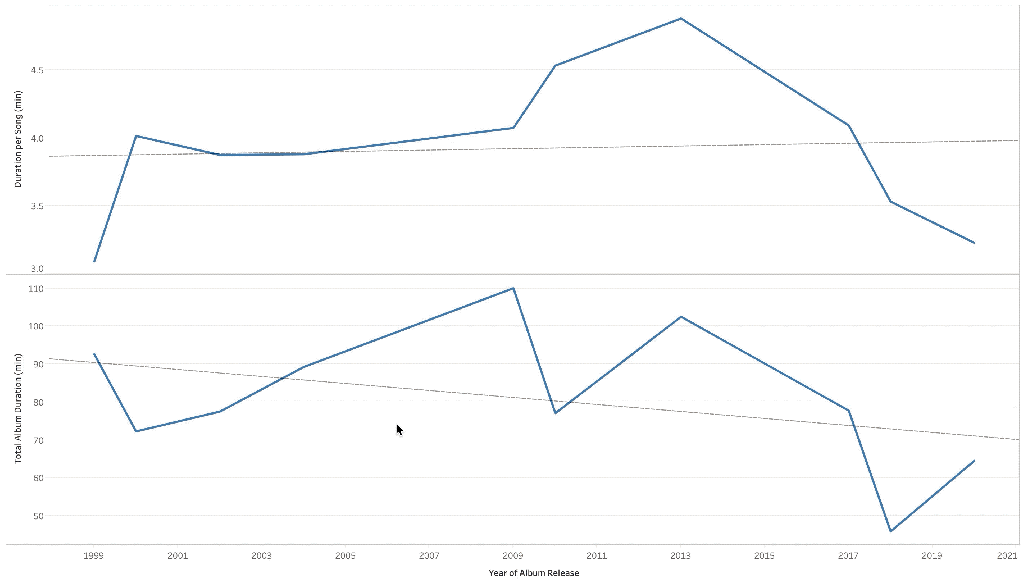
a bit heavy, takes 6 mins
Having worked on a project aimed towards improving health and wellness across hospitals in the US, I grew closer to understanding the issues faced by healthcare systems. Automation of operational tasks and proper technical infrastructure can eliminate the vast majority of these issues. With this in mind, I explored the advancement of Artificial Intelligence in Healthcare, the problems it can solve, and a few roadblocks along the way.
Machine Learning is transforming the healthcare industry by changing the outlook on care delivery, operational optimization, and disease detection.
The Problems
Enterprises in healthcare have long been troubled by problems like maintenance of health records, identification of care programs, early disease diagnostic, insurance fraud, waste, and abuse (FWA), time spent on medical imaging, and outbreak prediction for diseases. They are now looking towards machine learning (ML) techniques and artificial intelligence (AI) systems for the solution.
The US Healthcare system alone generates approximately 1 trillion gigabytes of data annually. [1]

This data is both structured and unstructured, creating the need for a complex set of algorithms to make sense from it. Typical statistical methods work on confined problems making use of structured data to drive insights. ML is required to learn from highly complex datasets and derive a relation between multiple parameters informing experts of the multimodal facets of the issue.
How to make sense of this data?
Various ML techniques apply to the healthcare industry based on the specific problem and the intended outcome.
1. Disease detection and prediction uses supervised learning techniques where the model is trained on a set of target outcomes. This technique is implemented with expert opinions and structured datasets to predict the occurrence of diseases or ailments.
2. Medical image analysis is implemented using Computer Vision and deep neural networks (like CNN) as they include highly complex and undescribed variables in the dataset.
3. Unsupervised learning algorithms find their application in outbreak prediction as they can be used for clustering and anomaly detection.
4. Insurance fraud and patient record maintenance use techniques like Natural Language Processing (NLP) and deep learning to make sense from unstructured patient records and missing data.
Where is the value for AI?
AI in Healthcare is expected to grow at a CAGR of 50.2% from 2018 to 2026 and reach a market size of $150 billion. [2]
ML is projected to deliver 63% of that value. [3]
The specific use cases of ML that can be used to solve the problems in healthcare include Automation of Patient Health Records, Disease Outbreak Prevention, Early Detection of Chronic Diseases, Patient Journey Monitoring, Equipment Maintenance, Operational Scheduling, Fraud Detection, and Medical Imaging Diagnosis.
Top 2 Use Cases
1. Early Detection of Chronic Diseases
The total annual cost of chronic diseases in the US is $3.7 trillion which is close to one-fifth of the entire US economy.
This cost is expected to increase as the US population is aging. [4] Using ML and predictive analytics can help identify high-risk patients and develop tailored monitoring or care programs that can prevent a total cost of $30.8 billion related to chronic diseases. [5]
2. Operations Scheduling
Deep neural networks can be used for the optimization of operational scheduling by leveraging electronic health record (EHR) data and resource utilization patterns.
This alone can save USD 500k per Operation Room per year. [6]
Operational Scheduling will allow for better patient care and will ensure the availability of resources including nurses and staff.
Necessary Infrastructure

ML and Deep Neural Networks are expected to reach the plateau of productivity in the next 2-5 years. To maximize the value we can create through them, we need to have the infrastructure and human capabilities in place. The technological infrastructure as it pertains to these two use cases includes proper data collection and storage techniques, hardware capacity to train and deploy ML models, and an interconnected system of equipment (IoT).
An ML model is only as good as the data provided to it. The sophistication of data collection techniques is important to realize a sound and scalable AI system. The lack of high-quality data and ineffective privacy protection are hindering the growth of AI in healthcare. [7]
Readying the Human Capital
Not a black box. Interpretabe and usable by doctors.
Healthcare is different from other industries in the sense that there is an intricate and intimate relationship between healthcare providers and patients. The ML systems and algorithms in healthcare need to be transparent where the various metrics and decision criteria are clearly understood by the doctors or providers. This means the human capital must be data literate and trained about the impact of ML models on their decision chain. This will be a key factor in the acceptance of ML in healthcare. [1]

Photo by Stephen Dawson on Unsplash
Delivering value through AI
Current players in the market offer a comprehensive set of products that can be implemented in the healthcare industry to deliver value for these use cases. They should look to serve the industry using the Three Horizon Model i.e. through their current capabilities, emerging technologies, and future ventures.
1. Growing the current business
ML techniques that have applications like Predictive Maintenance of equipment, Sensor Health monitoring, and Continuous Analytics can deliver value for Operations Scheduling. These applications help monitor the systems and predict asset failure that results in lower downtimes. Machine Learning services and AI modeling platforms will empower organizations to deploy models that help optimal predictions for chronic diseases.
2. Emerging Opportunities
The second horizon for healthcare AI business is its emerging opportunities that will create value shortly and will require considerable investment. This includes investing in Natural Language Processing, Computer Vision, and Speech Recognition to deliver use cases like Medical Imaging Diagnostics, Patient Journey Monitoring, and Improved Patient Record Maintenance.
3. Imagining the Future
The third horizon contains planning for profitable growth down the line including partnerships with upcoming tech labs, diversification of resources and focus areas. The future techniques will go beyond the focus on resolving operational issues to delivering value to the healthcare industry through Personalized Care.
Anticipating the future needs of the industry and preparing for acceptance of ML will empower us to benefit from the advent of AI in Healthcare.
References:
[1] https://www.mckinsey.com/industries/pharmaceuticals-and-medical-products/our-insights/machine-learning-and-therapeutics-2-0-avoiding-hype-realizing-potential
[2] https://www.accenture.com/fi-en/insight-artificial-intelligence-healthcare
[3] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6616181/
[4] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6429690/
[5] https://hbr.org/2017/05/how-machine-learning-is-helping-us-predict-heart-disease-and-diabetes
[6] https://leantaas.com/wp-content/uploads/2019/01/OR-case-study-booklet-27-01_online.pdf
[7] https://www.cbinsights.com/research/report/ai-trends-healthcare/